
https://arxiv.org/abs/2409.05976
FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations
The rapid development of Large Language Models (LLMs) has been pivotal in advancing AI, with pre-trained LLMs being adaptable to diverse downstream tasks through fine-tuning. Federated learning (FL) further enhances fine-tuning in a privacy-aware manner by
arxiv.org
arXiv 2024 논문이다.
https://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
LoRA에 대한 이해가 선행되어야 하니 위 논문을 읽고 올 것을 추천한다. 간단히 말해서, LoRA는 large model의 full parameter를 fine tuning하는 대신 rank-decomposed된 행렬 A, B를 생성하여 이 행렬만 업데이트하는 방식으로 fine tuning을 진행하는 것이다. 기존에는 방대한 리소스가 들었던 반면 LoRA를 이용하면 trainable parameter 수가 훨씬 줄어드는 장점이 있다. 모델 크기가 클수록(d가 커질수록) 이 효과는 극대화된다(LoRA의 rank r<<d 이므로).

- We introduce a new approach called FLORA that enables federated fine-tuning on heterogeneous LoRA adapters across clients through a novel stacking-based aggregation method
- noise-free and seamlessly supports heterogeneous LoRA adapters
- It can naturally accommodate heterogeneous LoRA settings, since stacking does not require the local LoRA modules to have identical ranks across client
Related Works
FedIT: integrating LoRA with FedAvg, 서버가 local LoRA를 단순 평균 식으로 합쳐서 global LoRA를 생성하는 과정에서 노이즈가 발생한다.

Method
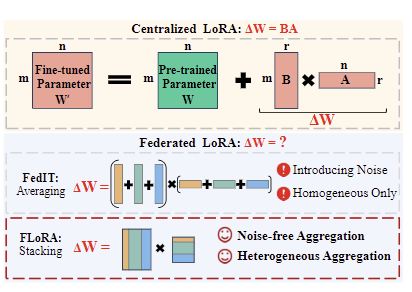
클라이언트마다 LoRA 랭크가 다를 수 있는데, 기존 방식은 이를 고려하지 못하고 일괄적인 크기의 매트릭스만을 집계한다(Homogeneous Only). FedIT의 단순 평균화 방식이 모델 업데이트에 노이즈를 생성하는 문제를 해결하기 위해, FLoRA는 로컬 LoRA 모듈을 stacking하는 aggregation 방식을 취한다.
1. 각 클라이언트는 사전 학습된 LLM을 기반으로 로컬 데이터를 사용하여 LoRA 모듈을 파인튜닝
2. 파인튜닝된 로컬 LoRA 모듈들은 서버로 전송되며, 서버는 이 모듈들을 스태킹하여 글로벌 LoRA 모듈을 생성 즉, 서버 측에서 스태킹된다.
3. 생성된 글로벌 LoRA 모듈은 클라이언트들에게 배포되어 로컬 모델을 업데이트하는 데 사용됨
스태킹 방식이 정확히 뭔지 알아보자.
Stacking Method

클라이언트에서 받은 Ai, Bi 행렬을 각각 low-wise, column-wise로 집계한다. 여기서 클라이언트마다 rank가 다르더라도 스태킹 방식으로 집계하기 때문에 문제가 되지 않는다. 최종적으로는 스태킹된 A, B를 matmul하여 global LoRA를 생성한다. 다음 라운드에서 업데이트된 LoRA 모듈을 각 클라이언트에 전송한다.
Experiments
모델: TinyLlama(11억 파라미터)와 Llama, Llama2(각각 70억 파라미터)의 다양한 버전을 사용
데이터셋: Databricks-dolly-15k, Alpaca 및 Wizard 데이터셋을 사용하여 QA 태스크와 챗 보조 태스크를 평가
클라이언트 설정: 10개의 클라이언트를 비독립적으로 선택하여 실험
베이스라인:
FedIT: 이질적인 LoRA를 지원하지 않는 SOTA 연합학습 파인튜닝 방법
Zero-padding: 이질적인 LoRA를 지원하기 위해 FedIT에 제로 패딩을 적용한 방법.
Centralized Fine-tuning: 동일한 하이퍼파라미터와 설정으로 FLORA와 비교
Standalone: 클라이언트가 사전학습 모델을 독립적으로 파인튜닝하는 방법

homogeneous, heterogeneous LoRA 모두에서 FLoRA의 성능을 각 조건의 baseline과 비교했을 때, 두 경우 모두 FloRA에서 우수한 성능을 보였다. task에 따라 차이가 있지만 homogeneous LoRA 조건에서 중앙집중식 학습보다 더 뛰어난 성능을 보이는 것도 관찰할 수 있다.

standalone 상황(클라이언트에서 pre-train 모델을 독립적으로 파인튜닝)에서의 각 llm task별 성능 차이. 각 태스크마다 최적의 rank가 있는 걸 볼 수 있다. 또한 클라이언트가 자기 자신의 로컬 데이터만으로 학습하는 것보다 더 나은 일반화 능력을 가진 글로벌 모델에서 성능이 좋은 경향이 있다.

scaling factor(위 그림에서 x축)에 따라서도 모델 성능이 달라진다. 데이터셋마다 최적의 스케일링 팩터가 다르지만 일반적으로 더 높은 수치에서 더 나은 성능을 기록한다. scaling factor는 아래와 같이 정의한다.

Contribution
- noise-free aggregation of local LoRA modules
- leading to faster convergence and improved performance
- supports heterogeneous LoRA ranks across clients
- surpasses SOTA methods for both homogeneous and heterogeneous settings
Limitation
서버가 스태킹된 LoRA 모듈을 클라이언트에게 보내는 과정에서 communication cost가 발생한다. 모든 클라이언트에게 보내야 하기 때문에...
클라이언트의 데이터 분포나 특성에 따라 adaptive한 scaling factor를 취하는 방식으로 성능을 올릴 수 있을 것 같다.
졸업 논문 주제 잡고 있는데 힘들다... problem statement가 제일 어려워