
오늘 리뷰할 논문은 2023년 NIPS에 publish 되었던 LLM-Pruner이다.
https://openreview.net/forum?id=J8Ajf9WfXP
LLM-Pruner: On the Structural Pruning of Large Language Models
Large language models (LLMs) have shown remarkable capabilities in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which...
openreview.net
멀티모달, LLM 등으로 대표되는 large model은 방대한 파라미터 수와 거대한 모델 크기 때문에 온디바이스뿐만 아니라 서버에서도 모델을 돌리는 데 많은 리소스가 든다. 마찬가지로 대형 모델을 특정 데이터에 specific 하게 파인튜닝 하기도 어렵다. 이러한 이유로 모델 경량화 후 파인튜닝하려는 연구가 진행되었는데, 모델의 크기를 가볍게 만드는 기법 중 하나가 프루닝(pruning)이라고 보면 된다.
LLM-Pruner는 그래디언트 크기 기반으로 중요하지 않은 LLM의 가중치 모듈을 선택적 삭제하는 알고리즘을 가진다. 뿐만 아니라, pruning으로 저하된 성능을 LoRA를 이용한 파인튜닝으로 복구하는 과정을 거친다. 이 복구 과정은 50K 데이터, 1개 GPU로 3시간 안에 빠르게 완료된다. 정리하면 아래와 같은 contribution이 있다.
1. Task-agnostic : task-specific하게 파인튜닝하여 특정 태스크 이외의 다른 질문에는 성능이 좋지 않은 다른 모델과 달리, LLM-Pruner는 모든 태스크에 일반적으로 좋은 성능을 유지한다. 즉, LLM의 zero-shot capability를 유지하면서도 가볍게 압축하는 것이다.
2. 빠른 회복 : 모델의 방대한 훈련 데이터 의존도를 줄여, 적은 양의 데이터셋으로 빠른 시간 안에 pergormance recovery를 진행할 수 있다.
Introduction
LLM은 탁월한 언어 이해 및 생성 능력을 보여주지만, 이러한 성능은 거대한 모델 크기와 관련이 있다. 개인 PC에서 LLM을 훈련시키는 건 불가능하고, 배포, 추론 및 훈련 과정에서 많은 비용이 발생한다. 따라서 이 연구에서는 LLM을 특정 작업에 의존하지 않고, task-agnostic한 방식으로 압축하려고 한다. 특정 데이터셋에 대한 의존성을 최소화하면서도 LLM의 기능을 보존할 수 있도록 하는 것이다.
(task-agnostic에서 agnostic=불가지론적 이라고 번역되는데(?ㅋㅋ), 그냥 task에 상관 없이~ 의미 정도로 받아들이면 된다.)
Method

각 메소드 특징을 비교해 보면 이렇다.
1️⃣ Task-Specific Compression
- 특정 작업(Task)에 맞게 모델을 압축하고 별도의 파인튜닝을 진행함.
- 작업에 대한 추가 데이터셋이 필요하며, 범용적인 LLM 능력을 유지하기 어려움.
2️⃣ TinyBERT
- KD 기반으로 작은 모델로 압축하여, 약 20GB의 데이터(코퍼스)를 활용하여 지속적인 훈련(3.5일, 4 GPU 사용)이 필요함. 시간도 오래 걸리고 일부 성능이 손실됨.
3️⃣ LLM-Pruner (제안된 방법)
- 50MB의 작은 데이터셋만 사용하고, 단 3시간(1 GPU)으로 훈련 가능.
- 여기서는 그래디언트 기반의 구조적 프루닝 (가중치 Wi의 중요도를 손실 변화량을 기반으로 평가)을 사용하고, LoRA로 성능을 복구함. 제거 시에도 모델의 사전 학습된 지식을 최대로 보존함.
- task-specific한 다른 파인튜닝 모델과 다르게, 제로샷 성능 유지 가능
구조적 프루닝?
Structued pruning은 전체 네트워크의 특정 구조(예: 뉴런, 채널, 층, 주어진 블록 단위)를 제거하는 방법이다. 예를 들어, CNN에서 비효율적인 필터를 제거하여 모델을 압축하는 채널(필터) 프루닝, 특정 뉴런(노드) 단위로 제거하여 경량화하는 뉴런 프루닝, 덜 중요한 레이어를 삭제하는 레이어 프루닝 등이 있다. 이렇게 프루닝을 진행하면 연산량이 크게 절감되고 GPU/TPU 최적화가 쉽다는 장점이 있다. 반대로 중요한 구조를 실수로 삭제하면 모델 성능이 급격히 저하될 수 있기 때문에 어떤 부분을 제거할지 신중히 결정해야 한다.
Unstructued pruning은 제거 단위가 개별 가중치로 축소된다. 주요 기법으로는 절댓값이 작은 가중치를 제거하거나, 학습 중 gradient의 변화량을 분석해서 중요도가 낮은 가중치를 제거하는 방식 등이 있다. 유연성이 높으면서 미세하게 조정 가능하다는 장점이 있지만, sparse 연산이 연산 비용을 증가시키는 단점이 있다.
LLM-Pruner 같은 대형 모델에서는 주로 구조적 프루닝을 진행하는데, 이 논문에서는 이러한 방식이 하드웨어 최적화에 용이하고 모델 경량화 효과를 극대화할 수 있어 채택했다고 설명하고 있다. Pruning 과정은 두 단계로 이루어진다.
Discover All Coupled Structure in LLMs
구조적 프루닝을 진행하기 위해서는 먼저 모델에서 어떤 부분이 서로 연관성을 가지는지를 찾아야 한다. LLM-Pruner는 각 뉴런의 입/출력 차수를 정의하여 coupled structures를 자동으로 찾아낸다. 두 뉴런의 종속성은 아래 식으로 정의한다. Deg의 위첨자 -는 뉴런의 입력 차수, +는 출력 차수를 의미한다.
$$ N_j \in \text{Out}(N_i) \land \deg^-(N_j) = 1 \Rightarrow N_j \text{ is dependent on} N_i $$
$$ N_i \in \text{In}(N_j) \land \deg^+(N_i) = 1 \Rightarrow N_i \text{ is dependent on} N_j $$
이런 식으로 모델의 모든 뉴런을 initial trigger로 사용하여 의존성을 분석한다. 이 과정은 반복적으로 진행되어 더 이상 의존성이 발견되지 않을 때까지 계속된다. 이러한 결합 구조를 자동으로 식별하고 추출할 수 있으므로 시간과 노력이 크게 줄어든다.
Grouped Importance Estimation of Coupled Structure
그룹화를 끝냈으면 importance 기반으로 어떤 구조를 삭제할 것인지 정해야 한다. Vector-wise Importance와 Element-wise Importance를 모두 고려하여 Group Importance를 측정한다.
Fast Recovery with Low-rank Approximation
아무리 중요하지 않은 구조 위주로 삭제했다지만, 프루닝 이후 모델 성능은 떨어지기 마련이다. 성능 회복을 위해서 Low-rank Approximation 방법을 사용하여 프루닝된 모델을 post-train 한다. LoRA는 이전 포스트에서도 언급한 적이 있는데, 자세히 알기 위해서는 2021년 LoRA 논문을 읽고 오는 걸 추천한다.
논문 리뷰: FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations
https://arxiv.org/abs/2409.05976 FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank AdaptationsThe rapid development of Large Language Models (LLMs) has been pivotal in advancing AI, with pre-trained LLMs being adaptable to div
jaehee831.tistory.com
LoRA에 따라 forward propagation 공식은 아래와 같다.
$$ f(x) = (W + \Delta W) X + b = (Wx + b) + (PQ)X $$
$$ \Delta W = PQ, \quad P \in \mathbb{R}^{d^- \times d}, \quad Q \in \mathbb{R}^{d \times d^+} $$
Experiments
LLM-Pruner의 성능을 실험하기 위해 task-agnostic setting에서 일반 상식 추론 데이터셋(BoolQ, PIQA, HellaSwag 등)을 이용했다. LLaMA-7B 및 13B 압축 모델을 사용했다.
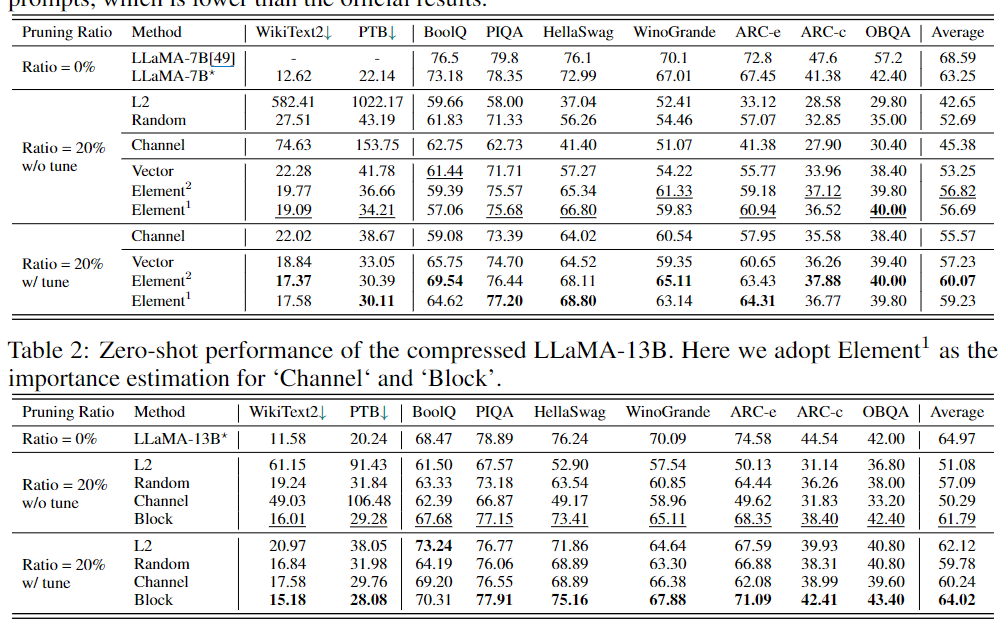
이 표는 다양한 모델에서의 프루닝 비율에 따른 성능 결과를 보여준다.
- Pruning Ratio: 모델에서 제거할 파라미터의 비율
- Method: LLaMA-7B/13B 원본 모델 성능, 랜덤 선택한 파라미터 제거 방법(Random), 의존성 구조를 고려한 제거 방법(Channel) 등의 방법을 비교
- Benchmark Dataset: WikiText2, PTB - 언어 모델에 대한 일반적인 평가, BoolQ, PIQA 등 - 다양한 추론 및 질문 응답 평가

제로샷 성능은 모델이 특정 작업에 대해 추가적인 학습 없이도 수행할 수 있는 능력을 의미한다. LLM-Pruner는 다양한 방식으로 제로샷 성능을 평가하였으며, 특히 압축된 모델이 원본 모델에 비해 얼마나 잘 수행되는지를 보여준다. 모델이 20%의 파라미터를 줄인 경우에도 상당한 성능을 유지할 수 있었으며 후처리(post training)을 통해 성능이 향상된 것을 알 수 있다. 반면 50%의 파라미터를 줄였을 때에는 성능 저하가 두드러지게 나타난다.
Conclusion
본 논문에서는 LLM-Pruner라는 구조적 프루닝 방법을 제안하고 있다. LLM-Pruner는 LLM을 task-agnostic하게 압축하여, 원래의 훈련 데이터에 대한 의존도를 최소화하고 언어 능력을 보존하는 것을 목표로 한다.
프루닝을 위해서는 우선 모델 내의 각 뉴런을 반복적으로 검토하여 의존성 그룹(coupled structure)을 식별하고, LLM의 의존성 그래프를 구성한다. 이후 group importance를 gradient 변화량 크기를 기반으로 식별한다. 이후, LoRA를 활용하여 가지치기된 모델의 recovery를 빠르게 진행할 수 있다.