
오늘 리뷰할 논문은 SemiFL이다. (NeurIPS 2022)
로컬 서버가 모델의 훈련을 전담하는 보통의 중앙집중식 학습방식과 다르게, 서버와 클라이언트가 연합하여 모델을 훈련하는 학습환경인 연합학습(Federated Learning)에 관한 이야기이다. 또한 supervised learning(지도학습)과 unsupervised learning(비지도학습)의 중간인 semi-supervised learning(준지도학습) 상황에서의 문제를 다루고 있다. 즉 라벨링이 되어있는 데이터와 그렇지 않은 데이터가 공존하는 상황이다.
https://arxiv.org/abs/2106.01432
SemiFL: Semi-Supervised Federated Learning for Unlabeled Clients with Alternate Training
Federated Learning allows the training of machine learning models by using the computation and private data resources of many distributed clients. Most existing results on Federated Learning (FL) assume the clients have ground-truth labels. However, in man
arxiv.org
Introduction
Semi-Supervised Learning에서의 Federated Learning은 어떻게 이루어질까?
대부분 클라이언트는 unlabeled data를 가지는 경우가 많다. 대표적으로 의료 데이터에서, 큰 대학병원(서버)은 환자 데이터를 보고 병명을 진단할 수 있지만 지역 병원(클라이언트)은 전문성의 부재로 그렇지 못한 경우이다. 하지만 환자의 의료 데이터를 전송하는 건 보안 문제에 걸리기 때문에 함부로 할 수 없다. 본 논문에서는 서버 측 소량의 labeld data와 클라이언트의 다수 unlabeled data를 가지고 학습하는 이러한 상황, 즉 Semi-Supervised Federated Learning (SSFL)에서 효율적으로 작동하는 SemiFL 프레임워크를 제안한다.

Method
Strong Data augmentation
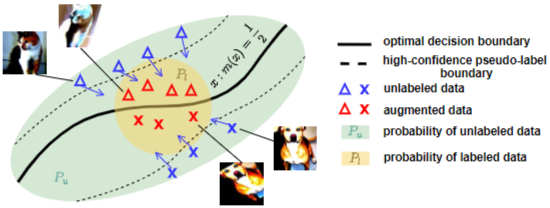
데이터 증강 방식 중 strong data augmentation은 기존의 데이터를 강한 증강(큰 회전, 저품질로 변환, RGB 색상 변경 등)으로 변형해서, 모델의 robustness를 높이는 역할을 한다. 준지도 학습이기 때문에 라벨링 되지 않은 데이터의 라벨을 예측하는 pseudo-labeling 과정이 필요한데, 이것도 증강 데이터를 대상으로 진행한다. 그림에서 보면 노란색 영역이 labeled data의 확률분포공간인데, unlabeled data X를 maneuver 한 X'을 만든 뒤 X'을 이 확률 공간으로 매핑하여 (X', Y)를 생성하는 것을 볼 수 있다. 여기서 hard threshold를 사용하는 것은 confidence를 높이기 위함이다. (SVM에서 hard margin, soft margin의 개념과 유사한 듯)
Alternate Training

기존 SSFL 알고리즘은 통신 라운드에서 클라이언트와 서버가 동시에 학습을 진행한다. 따라서 준지도학습에서 클라이언트가 라벨이 없는 데이터에 대해 수도라벨링을 할 때, 클라이언트-서버가 서로 소통하지 않고 진행한다. 이렇게 되면 매 통신 라운드마다 서버의 적절한 피드백이 없어, 수도라벨링 품질이 떨어지는 문제가 생긴다. 훈련을 진행할수록 성능이 저하되는 것이다. 이 문제를 해결하기 위해 SemiFL은 alternate training 방식을 사용한다. 말그대로 서버와 클라이언트가 교대로 모델을 훈련하는 것이다.
(a) FedMatch, FedRGD 등의 기존 SSFL 메소드가 사용하는 vanilla combination 방식. labeled data로부터 훈련한 서버 모델과 unlabeled data로부터 훈련받은 클라이언트 모델을, 각 communication에서 매 배치마다 병렬적으로 aggragate한다. 그리고 로컬에서 unlabeled data에 대해 수도라벨링을 진행하여 가짜 라벨을 만든다. 이 기존 SSL 메소드를 연합학습에 적용했을 때 성능 저하가 발생한다.
(b) SemiFL의 학습 방식으로, 글로벌 모델이 매 통신 라운드마다 클라이언트가 업데이터한 모델 파라미터를 가지고 글로벌 모델 파인 튜닝을 진행한다(fine-tune global model with labeled data). 이 파인튜닝 과정이 모델의 성능 저하를 막는다. 다음 라운드의 수도 라벨링 과정에서, 이전 라운드의 업데이트된 글로벌 모델 파라미터를 받아 사용하기 때문에 로컬 훈련 에폭동안 degrade가 일어나지 않는다.
Algorithm

M개의 로컬 클라이언트와 1개의 서버에 대해 학습을 진행한다고 했을 때 인풋 파라미터에는 각 클라이언트의 unlabeled data, activity rate C, 통신 라운드 수 T, 로컬 에폭 E, 배치 사이즈, 학습률 등이 들어간다. 초기의 서버/클라이언트 모델 파라미터도 (보통 임의로) 인풋으로 넣어준다.
시스템은 크게 서버 단과 클라이언트 단으로 동작하는데, 우선 서버가 글로벌 모델을 업데이트하고 이번 통신 라운드에 참여하는 클라이언트에게 데이터를 분배한다. 클라이언트는 병렬적으로 학습을 진행하고, 업데이트한 가중치를 서버에 전송한다. (이때 서버에 데이터가 아닌 모델 파라미터를 전송한다. 연합학습의 주요 목적인 데이터 프라이버시 때문이다.) 서버는 클라이언트로부터 받을 가중치를 가중 평균으로 집계하고, 서버 모델을 업데이트한다(fine-tuning). 이 일련의 동작이 하나의 통신 라운드에서 발생한다.
좀 더 자세히 알아보면

서버는 labeled data를 가지고 각 배치에 대해 훈련을 진행한다. 클라이언트는 약한 증강(weak-augmented) 데이터를 가지고 수도 라벨링한 데이터셋을 생성한다. 그리고 FixMatch 데이터셋을 생성한다. 이는 일정 신뢰도 이상인 high-confidence dataset으로, 성능 저하를 막기 위함이다. 이때 fix에 아무 데이터도 없다면, 훈련을 멈추고 서버에 전송하지도 않는다. fix에 데이터가 있다면, Mixup 데이터셋을 생성할 차례. MixMatch는 FixMatch 데이터셋에서 복원추출한 데이터로 이루어져 있으며, FixMatch와 같은 크기로 구성된다. 이제 E 에포크동안 각 배치(fix, mix)에 대해 클라이언트에서 훈련을 진행한다. 최종 모델 파라미터는 fix와 mix 데이터의 손실을 일정 비율(하이퍼파라미터 lambda)로 반영해 업데이트한다.
- mixup dataset을 생성하는 이유? FixMatch dateset은 high-confidence 데이터로 이루어져 있다. 이 데이터만 가지고 학습하면 라운드가 진행될수록 loss는 계속 줄어들고 성능 향상이 더디게 일어날 것이다. 그래서 모델의 빠른 수렴(그리고 model generality...?)을 위해서 일정 비율로 mixup data loss도 반영해 학습을 진행하는 것 같다.
Experiments
아래 실험 환경에서 진행했다.
- 모델/데이터: Wide ResNet28x2 (CIFAR10, SVHN), Wide ResNet28x8 (CIFAR100)
- 100 clients, activity rate C=0.1 (communication round 당 참여하는 client 수)
- 데이터 구분: IID, balanced Non-IID(각 client의 샘플 사이즈가 동일, 최대 K개 클래스), unbalanced Non-IID (Dirichlet distribution을 따라 샘플링)

baseline(Fully/Partially Supervised)은 labeled data에 대해 모델 훈련을 진행한 결과이다. SemiFL은 partially supervised한 상황, 즉 클라이언트가 unlabeled data를 가진 상황에서 labeled data를 가지고 학습하는 글로벌 모델의 성능을 크게 향상했다. 또한 IID 상황에서 SOTA-SSL 메소드와 comparable 한 성능을 냈다. 하지만 labeled data가 적어질수록 중앙집중식 SSL 방식보다 성능이 떨어지는 것을 볼 수 있다. 물론 현존하는 SSFL 메소드보다는 훨씬 좋은 성능을 내고, Non-IID 한 상황으로 갈수록 그 차이가 커진다.

ablation study 결과 SemiFL의 글로벌 모델 파인튜닝 과정이 성능 향상에 큰 영향을 준다는 것을 알 수 있다.
Comment
SemiFL은 SSFL 메소드를 현존하는 FL, SSL 방식과 comparable 한 수준으로 구현했다는 점에서 novelty를 가진다. 단순히 FL과 SSL 학습을 조합해 서버와 클라이언트가 동시 학습하는 기존 방식과 달리, alternate training과 global model의 fine tuning 과정을 통해 현존하는 SSFL 메소드 중 SOTA를 달성하였다.
연합학습 과제 중 하나인 정보의 비대칭성을 고려했을 때 가치있는 해결방안을 제시한 논문인 것 같다. 더욱 높은 성능을 달성할 수 있는 학습 방법이 개발되면 좋겠다.