
요즘 공부하는 Semi-Supervised Learning(SSL) 분야의 주요 연구들을 정리해보고자 한다.
Semi-Supervised Learning(SSL)
SSL은 말 그대로 supervised learning과 unsupervised learning의 중간 상태이다. unlabeled 데이터와 labeled 데이터가 동시에 존재하고, 둘 다 모델 학습에 이용하는 시나리오이다. 보통 소수의 labeled와 다수의 unlabeled가 존재하는 경우를 다룬다.
SSL 시나리오에서 FixMatch라는 알고리즘이 유명한데, unlabeled 데이터를 활용하여 모델의 성능을 향상하는 간단하면서도 효과적인 방법을 제시하고 있다.
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence (NIPS ' 20)
https://arxiv.org/pdf/2001.07685
구글 리서치 논문이며, 작성일 기준으로 인용수 4489회이다.
딥러닝 모델은 일반적으로 지도 학습을 통해 훈련되며, 이는 labeled 데이터셋을 필요로 한다. 하지만 데이터에 label을 붙이는 작업은 많은 인력과 비용을 필요로 하며, 특히 의료 분야처럼 전문가의 label이 필요한 경우에는 더욱 그렇다.
이를 고려해 더 실용적인 시나리오인 SSL이 등장했다. SSL은 unlabeled 데이터를 활용하여 모델 성능을 향상시키는 방법이다. unlabeled 데이터는 labeled 데이터에 비해 쉽게 얻을 수 있으므로, SSL은 labeled 데이터 부족 문제를 해결하는 데 효과적이다.
FixMatch는 consistency regularization과 pseudo-labeling이라는 두 가지 SSL 방법의 조합을 단순화한 알고리즘이다.
weakly-augmented된 unlabeled 이미지에 대한 모델의 예측을 사용하여 pseudo-label을 생성하고, high-confidence 예측에 대해서만 pseudo-label을 유지한다. 그런 다음, strongly-augmented 된 동일한 이미지에 대해 pseudo-label을 예측하도록 모델을 훈련한다.
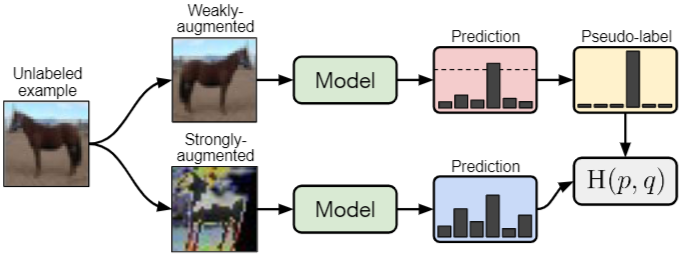
- Pseudo-label: 모델이 weakly augmented image에 대해 예측한 확률 분포에서 가장 높은 확률값을 가지는 클래스를 hard label로 변환한 것이다. 이 pseudo-label은 모델이 높은 신뢰도를 가진다고 판단하는 레이블을 의미한다.
- H(p, q): Cross-entropy loss 함수로, Pseudo-label(p)과 strongly augmented image에 대한 모델의 예측(q) 사이의 cross-entropy를 계산하여 모델이 pseudo-label과 일치하는 예측을 하도록 학습한다.
Fixmatch의 기법인 consistency regularization과 pseudo-lebeling에 대해 자세히 알아보자.
Consistency regularization
$$\sum_{b=1}^{\mu B} \|p_m(y \mid \alpha(u_b)) - p_m(y \mid \alpha(u_b))\|_2^2$$
이 수식은 레이블이 없는 데이터에 대한 Consistency Regularization 손실을 계산한다. Consistency Regularization은 모델이 동일한 입력의 변형된 버전에 대해 유사한 예측을 해야 한다는 아이디어를 기반으로 한다. L2 Norm을 사용하여 두 확률 분포(같은 입력에 대한 두 예측) 간의 거리를 계산한다.
Pseudo-Labeling
$$\frac{1}{\mu B} \sum_{b=1}^{\mu B} \mathbb{1}(\max(q_b) \geq \tau) H(\hat{q}_b, q_b)$$
이 손실 함수는 모델이 unlabeled 데이터에 대해 생성한 인공 레이블을 사용하여 모델을 학습시키는 데 사용된다. 모델이 예측에 대해 충분히 확신하는 경우 (high confidence) hard 레이블 q_hat과 모델의 예측 q_b 사이의 cross-entropy 손실이 계산된다. 이 손실은 unlabeled 데이터 배치에 대해 평균화된다.
단순한 알고리즘에도 불구하고, FixMatch는 CIFAR-10, CIFAR-100, SVHN, STL-10, ImageNet 등의 표준 SSL 벤치마크 데이터셋을 사용하여 진행한 실험에서 라벨이 매우 부족한 환경에서 좋은 성능을 보였다.
- 기여점:
- 매우 간단한 구조로 state-of-the-art 달성
- threshold 기반 confident filtering
- 한계점:
- open-set 환경에서는 성능 급락
- unknown class에 대한 구별 불가능
OpenMatch: Open-set Consistency Regularization for Semi-supervised Learning with Outliers (SIGIR ' 21)
https://arxiv.org/pdf/2105.14148
(작성일 기준 인용수 75회)
이 논문은 레이블되지 않은 데이터에 알려지지 않은 클래스(outlier)가 포함된 Open-Set Semi-supervised Learning(OSSL) 문제를 다루며, 이를 해결하기 위해 OpenMatch라는 새로운 프레임워크를 제안하고 있다. 주요 방법론은
- One-vs-All(OVA) 분류기를 사용하여 아웃라이어를 탐지하고, Soft Open-Set Consistency Regularization(SOCR)
너무 길잖아?손실을 통해 아웃라이어 탐지 성능을 향상하며, FixMatch를 적용하여 인라이어 분류 정확도를 높인다. - 이때 consistency learning은 known class만 사용한다. OOD(Out-of-Distribution)은 detect 후 학습에서 아예 제외하는 방식이다. 이후 기법에서 이 한계를 논의할 예정!
- 제안 기법은 여러 데이터셋에서 최신 기술 수준의 성능을 달성했으며, 레이블 되지 않은 데이터에서 보지 못한 새로운 아웃라이어까지 효과적으로 탐지할 수 있음을 보여주었다. 기존 fixmatch에 비해 강점인 부분이다.
나는 여기서 inlier/outlier와 labeled/unlabeled 개념이 헷갈렸는데
- Inlier (인라이어): 레이블이 있는 데이터셋에 포함되어 있는 클래스에 속하는 샘플을 의미한다. 즉, 모델이 이미 알고 있는 샘플. 레이블이 없는 데이터 중에서도 이전에 학습한 클래스에 속하는 샘플들은 inlier로 간주된다. OpenMatch의 목표 중 하나는 이러한 inlier 샘플들을 올바른 클래스로 정확하게 분류하는 것입니다.(ID classification)
- Outlier (아웃라이어): 레이블이 있는 데이터셋에서 한 번도 보지 못한, 새로운 카테고리에 속하는 샘플(unseen/unknown)을 의미한다. outlier는 레이블이 없는 데이터셋에만 포함될 수 있다.

Unlabeled Example(개 이미지)에 대해 두 가지 다른 data augmentation(Augmented 1 & Augmented 2)을 적용하여 두 개의 변형된 이미지를 생성한다.
* Data augmentation은 모델의 일반화 성능을 향상시키기 위해 이미지에 다양한 변환(예: rotation, cropping, flipping)을 적용하는 과정이다.
Data augmentation을 거친 이미지에서 특징을 추출하고(Feature Extractor), 추출된 특징을 바탕으로 입력 이미지가 inlier(known class)인지 outlier(novel class)인지 판단한다. 이때 One-Vs-All (OVA) classifiers를 사용하여 각 클래스에 대해 outlier score를 계산한다(Anomaly Score for Each Class). 이 score는 해당 샘플이 특정 클래스의 outlier에 얼마나 가까운지를 나타낸다.
Consistency Regularization은 Data augmentation을 거친 두 이미지의 anomaly score 간의 거리를 줄여서 outlier detector의 decision boundary를 부드럽게 만드는 과정이다. 이는 모델이 입력의 작은 변화에 덜 민감하게 만들고, outlier detection 성능을 향상하는 데 도움을 준다.
OVA loss

한마디로 정답 클래스에는 확신을 갖고, 가장 헷갈리는 다른 클래스는 더 확실히 구분하라는 목적의 loss이다. 모델이 known class를 더 명확하게 인식하고, unknown class는 known들과 확실하게 분리되도록 feature space를 정제하는 데 사용된다. Open-set 환경에서는 unknown class를 잘 분리하지 못하면, pseudo-labeling이 망가지고 전체 학습이 무너질 수 있기 때문에 중요한 부분이다.
- 첫 번째 항
→ 모델이 정답 클래스 y_b에 대해 “이건 확실히 나의 클래스야!”라고 높은 확률을 주도록 학습시킨다. - 두 번째 항
→ 반대로, 정답이 아닌 클래스 중 가장 혼동되는 클래스 하나를 골라, 그것에 대해 “이건 아닌 것 같아”라는 판단을 더 명확히 하도록 한다. hard-negative sampling이라고 한다.

- 기여점:
- 처음으로 open-set 환경에 특화된 SSL 프레임워크 제안
- 한계점:
- filtering 성능에 따라 전체 학습 성능 민감
IOMatch: Simplifying Open-Set Semi-Supervised Learning with Joint Inliers and Outliers Utilization (ICCV ' 23)
https://arxiv.org/abs/2308.13168
IOMatch: Simplifying Open-Set Semi-Supervised Learning with Joint Inliers and Outliers Utilization
Semi-supervised learning (SSL) aims to leverage massive unlabeled data when labels are expensive to obtain. Unfortunately, in many real-world applications, the collected unlabeled data will inevitably contain unseen-class outliers not belonging to any of t
arxiv.org
(작성일 기준 인용수 32회)
OpenMatch 같은 기존 OSSL 방식들은 outlier를 먼저 탐지해서 제거하는 방식(detect-and-filter)을 사용한다. 그런데 이 방식은 라벨이 적을수록 inlier(정상 샘플)도 같이 제외해버려서 성능이 더 떨어지는 역효과를 불러온다.
그래서 IOMatch는 "어차피 확실히 구분 못할 거면 그냥 같이 쓰자" 라는 철학을 가지고 있다. 즉, inlier/outlier 데이터를 따로 나누지 않고 같이 학습에 활용한다. 핵심 기법은 아래와 같다.
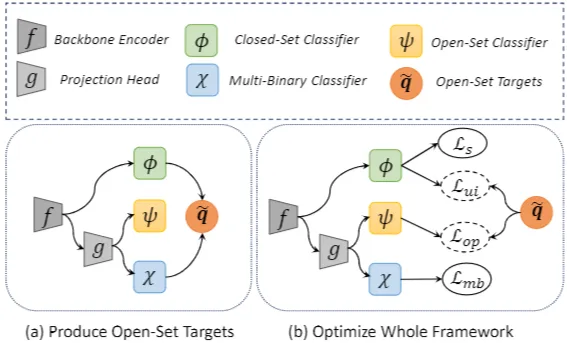
(a) Open-Set Targets 생성
- Backbone Encoder f :입력 데이터를 받아 특징을 추출한다.
- Projection Head g : 추출된 특징을 더 낮은 차원으로 축소한다.
- Closed-Set Classifier phi : 추출된 특징을 사용하여 labeled 데이터의 클래스를 예측한다.
- Multi-Binary Classifier chi : 각 샘플이 labeled 데이터의 각 클래스에 속할 가능성을 예측한다. 즉, 각 클래스별로 해당 샘플이 inlier인지 outlier인지 이진 분류를 수행한다.
- Open-Set Classifier psi : unlabeled 데이터를 open-set probability로 분류한다.
- Open-Set Targets tilde{q} : Closed-Set Classifier와 Multi-Binary Classifier의 예측을 융합하여 unlabeled 데이터에 대한 통합된 open-set classification 목표를 생성한다. 여기서 모든 outlier는 새로운 단일 클래스로 간주된다.
(b) 전체 프레임워크 최적화
생성된 open-set targets을 사용하여 전체 프레임워크를 최적화하는 과정이다. 이 과정에서 사용되는 손실함수는 다음과 같다.
- L_s : labeled 데이터에 대한 cross-entropy loss
- L_mb : Multi-Binary Classifier를 학습하기 위한 loss
- L_ui : unlabeled 데이터 중 inlier에 대한 loss
- L_op : unlabeled 데이터 전체(inlier 및 outlier)에 대한 loss
- 기여점:
- Open class 정보 활용하여 representation 개선
- 기존보다 높은 filtering 정확도 및 성능 향상
- 한계점:
- 고정된 신뢰도 임계값 사용으로 유연성 저하
- 논문에서 제시하는 class space 시나리오(labeled 데이터 클래스 모두가 unlabeled 데이터 클래스에 포함되는) 외에 다른 것도 있을 수 있음
이외에도 SCOMatch 등 다양한 SSL/OSSL 알고리즘 방법론이 있다. 기회가 된다면 다음에 다루어 보도록 하겠다!