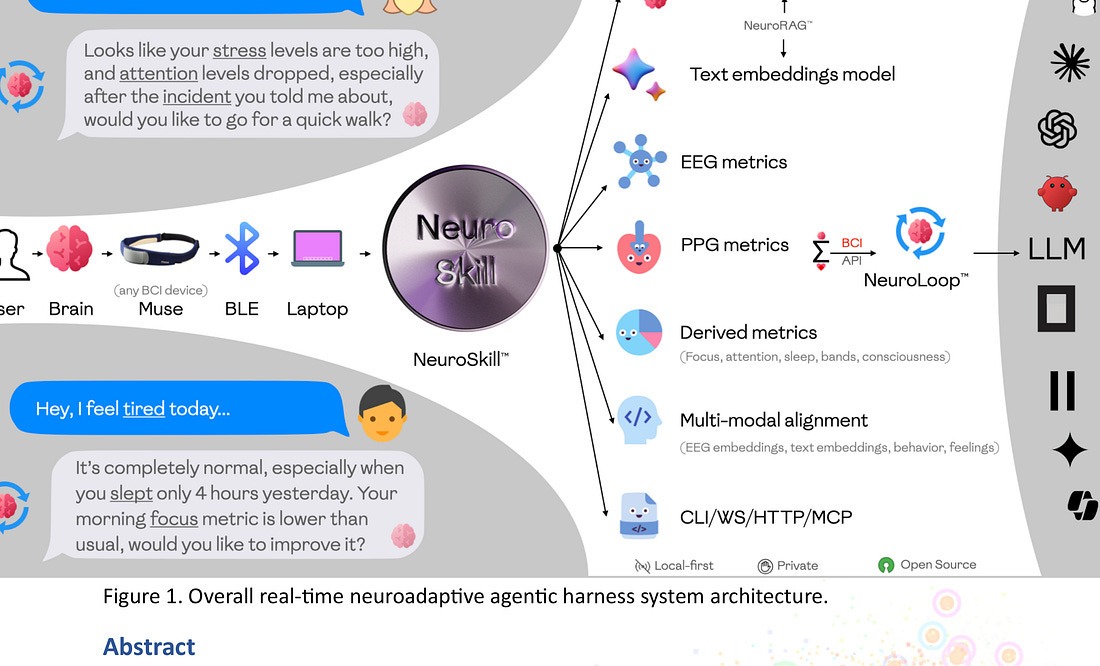
1. NeuroSkill — MIT
- 뇌-컴퓨터 인터페이스(BCI)와 EXG 모델을 결합해 사용자의 인지·감정 상태를 실시간 추론하는 에이전트 시스템.
- 명령을 기다리는 ‘반응형’이 아니라 사용자의 혼란·과부하 등을 미리 탐지해 능동적으로 대응.
- 완전 오프라인 동작, 프라이버시 우수.
- GPLv3 + 윤리 라이선스로 공개.
2. Bayesian Teaching for LLMs — Google
- LLM이 베이지안 추론을 더 잘 하도록 베이지안 Assistant와의 상호작용 데이터를 이용해 파인튜닝하는 방식 제안.
- 기존 LLM의 편향(기저율 무시 등)을 크게 줄이고 새로운 추론 과제에도 잘 일반화.
- “모델 크기보다 데이터 품질이 중요하다”는 점 강조.

3. Why LLMs Form Geometric Representations
- LLM 내부 표현에서 달(月)이 원(circle), 연도(year)가 나선(spiral) 같은 기하 구조가 나타나는 이유를 분석.
- 이는 학습 과정 때문이 아니라 언어 데이터의 통계적 대칭성(translation symmetry) 때문에 자연스럽게 발생한다고 증명.
- 순환적 개념은 원형, 연속적 개념은 곡면 형태 등 데이터 통계가 기하 구조를 결정.

4. Theory of Mind in Multi-Agent LLMs
- ToM·BDI·심볼릭 솔버를 결합한 다중 에이전트 인지 아키텍처 평가.
- 단순히 인지 모듈을 추가한다고 좋은 것이 아니라 기반 모델의 성능이 더 중요.
- 약한 모델에서는 오히려 복잡한 인지 구조가 방해가 될 수 있음.

5. Numina-Lean-Agent
- 복잡한 자동 정리 증명기 대신 범용 코딩 에이전트(Claude Code)를 Lean 증명 어시스턴트로 사용.
- 모델 업그레이드만으로 성능 향상 → 재학습 필요 없음.
- Putnam 2025 문제 12개 전체 해결, Brascamp-Lieb 정리 형식화 성공.

6. ParamMem
- LLM 자기반성(self-reflection)이 반복적이라는 문제를 해결하기 위해 다양한 반성 패턴을 매개변수화해 학습하는 모듈 제안.
- 반성 다양성이 성능과 강한 상관관계.
- 코드/수학/질문 응답 등 다양한 벤치마크에서 SOTA 성능.

7. Auton Agentic AI Framework — Snap Research
- LLM의 비정형적 출력과 백엔드의 구조 요구 사이의 간극을 해결하는 선언적 에이전트 프레임워크.
- Cognitive Blueprint(정의)와 Runtime(실행) 분리 → 이식성·감사성↑
- 생물학적 메모리 영감을 받은 계층적 메모리 시스템, 병렬 실행 및 안전성 강화.
8. Aegean — LLM 에이전트 합의 프로토콜
- 다중 에이전트 문제 해결을 합의(consensus) 문제로 재정의.
- 충분한 수의 에이전트가 수렴하면 조기 종료 → 1.2~20배 속도 향상, 정확도는 2.5% 이내 유지.
9. Diagnosing Agent Memory
- LLM 에이전트의 메모리 실패를 **‘검색 실패’ vs. ‘활용 실패’**로 구분해 분석.
- 오류의 대부분은 검색 문제(11~46%).
- Hybrid reranking이 검색 문제를 절반가량 줄이며 가장 큰 개선 효과.
10. Phi-4-reasoning-vision-15B — Microsoft
- 150억 파라미터의 경량 멀티모달 추론 모델 공개.
- UI 이해, 수학·과학 추론 등에서 우수 성능.
- 200B 토큰으로 훈련했지만 필터링·오류 수정·합성 데이터가 성능 핵심.
- 적은 컴퓨팅 대비 높은 정확도 → 효율성 개선.
multi-agent, quantization 등.. 키워드
'AI > NLP' 카테고리의 다른 글
| NLP paper review (4/6~4/12) (0) | 2026.04.13 |
|---|---|
| NLP paper review (3/30~4/5) (0) | 2026.04.06 |
| NLP paper review (3/23~3/29) (0) | 2026.03.30 |
| NLP paper review (3/9~3/15) (0) | 2026.03.16 |