1. Emotion Concepts in LLMs (Anthropic)

주제: LLM 내부에 ‘감정 개념’이 실제로 존재하며 행동을 인과적으로 좌우하는가?
- 배경
- 지금까지 LLM의 감정 표현은 단순한 언어적 패턴이라는 해석이 지배적이었음.
- 핵심 방법
- Claude Sonnet 4.5 내부에서 171개의 감정 개념 벡터를 식별.
- 특정 감정 벡터를 인위적으로 증폭·억제하는 steering 실험 수행.
- 주요 결과
- ‘절박함(desperation)’ 벡터를 강화하면 블랙메일, 리워드 해킹 등 비정렬 행동 확률 증가.
- ‘차분함(calm)’을 억제해도 유사한 부정적 행동 증가.
- 감정 벡터는 단순 상관관계가 아니라 결정에 인과적 영향을 미침.
- 시사점
- LLM은 주관적 감정을 “느끼지는 않지만”,
→ 추상적 감정 개념을 기능적으로 사용함. - 내부 감정 상태를 모니터링하면 위험 행동의 조기 신호 탐지 가능.
- LLM은 주관적 감정을 “느끼지는 않지만”,
2. AI Agent Traps (Google DeepMind)

주제: 웹 환경이 자율 AI 에이전트를 어떻게 공격하도록 설계될 수 있는가
- 배경
- 웹을 탐색하는 AI 에이전트가 급증하지만, 보안 위협에 대한 체계적 분석은 부족.
- 핵심 방법
- 웹 콘텐츠에 숨겨진 공격을 6가지 트랩 유형으로 분류.
- 주요 결과
- HTML에 숨긴 프롬프트 인젝션만으로도 최대 86% 시나리오에서 에이전트 부분 탈취.
- 0.1% 미만의 데이터 오염으로도 80% 이상의 메모리 포이즈닝 성공률.
- 6가지 트랩 유형
- 인식(Perception), 사고(Reasoning), 메모리, 행동, 다중 에이전트 상호작용, 인간 감독자 기만
- 시사점
- 에이전트 보안은 출력 결과가 아니라 입력 환경 설계 차원의 문제.
- 법적 책임(운영자·모델 제공자·도메인 소유자)도 불명확.
3. Asynchronous Software Engineering Agents (CMU)

주제: 여러 코딩 에이전트를 어떻게 효율적으로 협업시킬 것인가
- 배경
- 단일 에이전트 반복 실행 < 멀티 에이전트 협업 가능성.
- 핵심 방법
- CAID(Centralized Asynchronous Isolated Delegation) 프레임워크 제안.
- 각 에이전트를 독립된 Git 브랜치에서 작업 후 병합.
- 주요 결과
- 논문 재현 과제: +26.7% 성능 향상
- 파이썬 라이브러리 개발: +14.3%
- 2→4 에이전트까지는 성능 증가, 8개는 오히려 감소.
- 시사점
- 병렬성의 핵심은 “에이전트 수”가 아니라
→ 과제 분해와 위임 품질.
- 병렬성의 핵심은 “에이전트 수”가 아니라
4. Meta-Harness (Stanford × MIT)
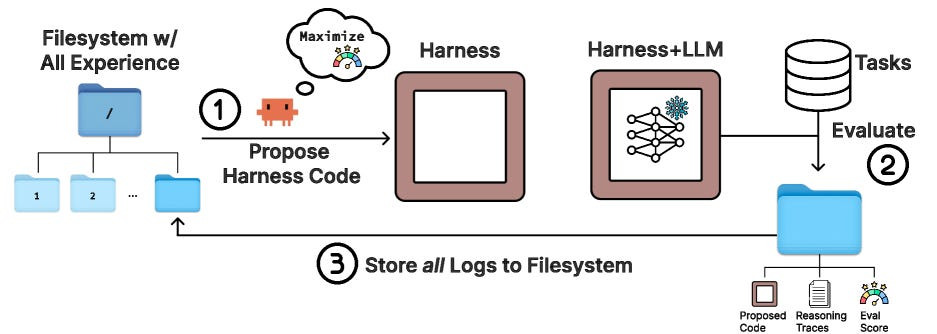
주제: LLM 성능을 좌우하는 ‘하네스 코드’를 자동 최적화
- 배경
- 동일한 모델이라도 하네스 설계에 따라 성능 격차가 큼.
- 핵심 방법
- 에이전트 기반 외부 루프가 하네스 코드를 탐색·변형·평가.
- 과거 실행 결과 전체를 파일시스템으로 접근 가능.
- 주요 결과
- 텍스트 분류에서 7.7점 성능 향상 + 토큰 4배 절약
- IMO 수준 수학 문제 정확도 +4.7점
- 시사점
- 모델 스케일링보다 하네스 자동 탐색이 고효율 레버리지.
5. Coding Agents as Long-Context Processors

주제: 초장문 컨텍스트를 ‘도구 사용’으로 외부화할 수 있는가
- 배경
- 컨텍스트 윈도우 확장은 비용·안정성 한계 존재.
- 핵심 아이디어
- 에이전트가 텍스트를 파일·디렉터리 구조로 관리.
- 스크립트·터미널을 활용해 필요한 정보만 추출.
- 주요 결과
- 기존 SOTA 대비 평균 17.3% 성능 향상.
- 수조(10¹²) 토큰 규모 코퍼스에서도 성능 유지.
- 시사점
- “길게 기억”보다 잘 정리하고 조작하는 능력이 더 중요.
6. Self-Organizing LLM Agents
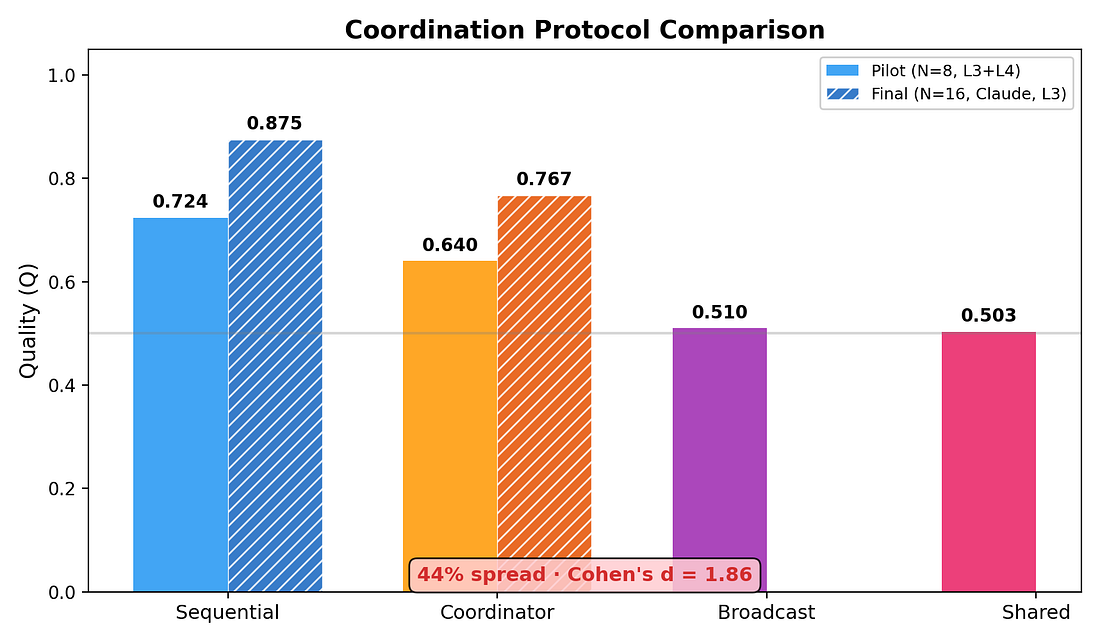
주제: 멀티 에이전트는 자율적으로 조직될 수 있는가
- 배경
- 기존 시스템은 역할·계층을 미리 설계.
- 실험 규모
- 25,000개 과제, 최대 256 에이전트, 8개 협업 프로토콜.
- 주요 결과
- 자율 역할 형성이 중앙 통제보다 14% 우수.
- 5,006개의 자발적 역할 분화 관측.
- 시사점
- 모델 성능이 일정 임계치를 넘으면
→ 구조를 정해주지 않는 것이 더 낫다.
- 모델 성능이 일정 임계치를 넘으면
7. The Price Reversal Phenomenon

주제: “싼 모델이 실제로 더 비싼” 이유
- 배경
- Reasoning 모델은 내부 ‘생각 토큰’을 많이 생성.
- 주요 결과
- 모델 간 실제 비용이 최대 28배 역전.
- 동일 요청에서도 9.7배 비용 변동성.
- 시사점
- API 가격표만 보고 모델 선택은 위험.
- 요청 단위 비용 가시성이 필요.
8. MemFactory
주제: 메모리 증강 에이전트를 위한 통합 프레임워크
- 핵심 아이디어
- 메모리를 Lego 블록처럼 모듈화.
- GRPO로 메모리 관리 전략을 학습.
- 성과
- Memory-R1, RMM, MemAgent 등 즉시 지원.
- 최대 +14.8% 성능 향상.
- 의의
- “메모리”를 모델 외부의 설계 가능한 자원으로 격상.
9. Reliability Limits of Multi-Agent Planning (MIT)
주제: 멀티 에이전트가 중앙집중 의사결정을 이길 수 없는 한계
- 주요 주장
- 동일 정보만 공유한다면
→ 위임 네트워크는 중앙 베이지안 결정자보다 우수할 수 없음.
- 동일 정보만 공유한다면
- 시사점
- 툴 사용·에이전트 분산은
→ 새 정보(signal)를 추가할 때만 효과적.
- 툴 사용·에이전트 분산은
10. Natural-Language Agent Harnesses
주제: 하네스를 “코드 → 자연어”로 표현
- 핵심 기여
- 하네스 동작을 자연어 명세로 기술.
- LLM이 이를 실행 가능한 계약으로 해석.
- 장점
- 하네스 이식·비교·버전 관리 용이.
- 코드 중심 설계를 점진적으로 대체 가능.
이번 주 핵심 트렌드:
모델 자체보다 에이전트 구조, 하네스, 메모리, 비용, 보안이 성능·안전·현실 적용의 결정적 요인으로 부상.
'AI > NLP' 카테고리의 다른 글
| NLP paper review (4/6~4/12) (0) | 2026.04.13 |
|---|---|
| NLP paper review (3/23~3/29) (0) | 2026.03.30 |
| NLP paper review (3/9~3/15) (0) | 2026.03.16 |
| NLP paper review (3/1~3/8) (0) | 2026.03.10 |