1. Neural Computers (Meta AI & KAUST)

배경
- 기존 컴퓨터: 프로그램 / 메모리 / I/O가 분리
- LLM·에이전트: “행동하는 모델”은 있지만 모델 자체가 컴퓨터는 아님
핵심 아이디어
- 모델의 은닉상태(latent state) 자체를 실행 중인 컴퓨터로 사용
- 계산, 메모리, 입출력을 하나의 신경망 런타임으로 통합
구현
- 비디오 생성 모델을 컴퓨터 인터페이스 학습에 사용
- NCCLIGen: 터미널 화면을 생성하며 명령어 실행
- NCGUIWorld: GUI 환경에서 마우스 이동·클릭·윈도우 전환 학습
- 실제 프로그램 상태 접근 없이 픽셀 + 사용자 행동만 보고 학습
의미
- “모델 + 외부 환경”이 아니라 모델 = 컴퓨터
- 장기적으로는 완전히 신경망 기반의 범용 계산 시스템(CNC)로 확장 가능
2. Memento: LLM이 스스로 컨텍스트를 관리하는 법 (Microsoft)

배경
- 긴 Chain-of-Thought → KV cache 폭증 → 메모리·속도 병목
핵심 아이디어
- 모델이 스스로 추론을 블록 단위로 나누고 요약
- 요약본(memento)만 남기고 원본 추론 토큰 삭제
작동 방식
- 추론 블록 종료 토큰 표시
- 해당 블록의 핵심 결론·중간값을 짧게 요약
- 원래 토큰은 KV cache에서 제거
- 이후 추론은 memento만 참조
결과
- KV cache 사용량 2–3배 감소
- 추론 속도 거의 2배
- 정확도 손실은 대체로 미미 (특히 대형 모델에서)
의미
- “더 긴 컨텍스트”가 아니라 컨텍스트를 다루는 능력이 중요함을 입증
- 실서비스에 바로 쓸 수 있는 기법
3. Memory Intelligence Agent (MIA)
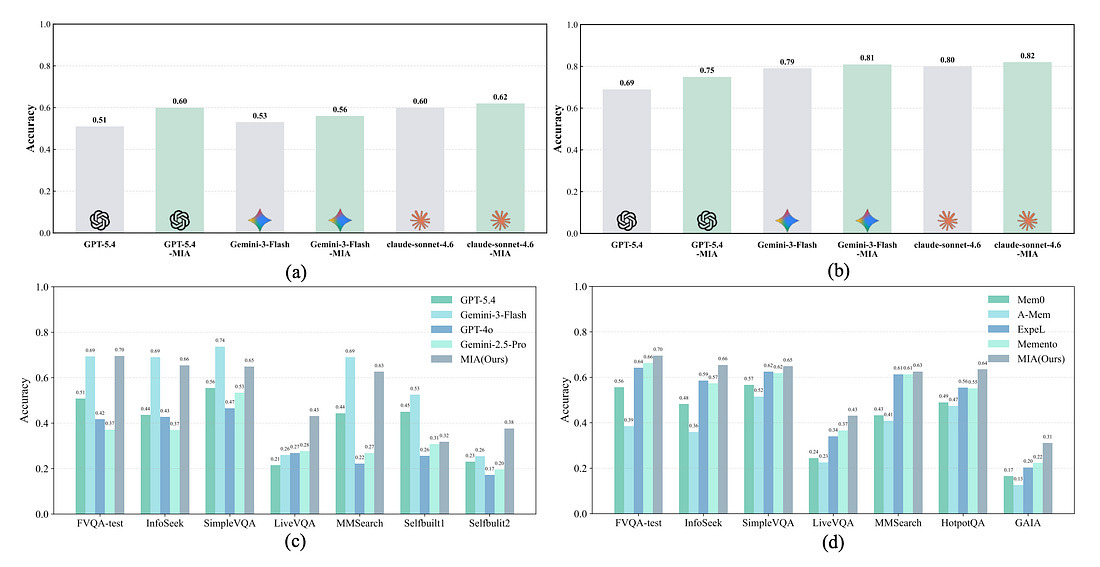
배경
- RAG/메모리 에이전트의 메모리는 대부분 정적 저장소
핵심 아이디어
- 메모리를 관리·계획·실행하는 별도 에이전트로 분리
- Memory Manager
- Planner
- Executor
주요 특징
- 양방향 메모리 변환
- 자주 쓰는 정보 → 모델 내부(파라메트릭)
- 드문 정보 → 외부 메모리(비파라메트릭)
- 추론 중 파라미터 업데이트 가능
- 테스트 타임 학습(Test-time learning)
결과
- LiveVQA 등에서 최대 +9% 향상
의미
- 메모리를 “검색 대상”이 아니라 적응적으로 진화하는 자산으로 취급
- 장기 에이전트·리서치 에이전트에 적합
4. Single-Agent vs Multi-Agent Systems (Stanford)

배경
- 다중 에이전트(MAS)가 항상 더 좋다는 암묵적 가정
핵심 주장
- 성능 향상의 상당 부분은 에이전트 수가 아니라 연산량 증가 때문
분석
- 토큰 예산을 동일하게 통제하면:
- 단일 에이전트 ≥ 다중 에이전트
- 정보이론 관점:
- 에이전트 간 전달은 정보 손실(Data Processing Inequality) 발생
의미
- MAS는 “설계 선택”이지 기본 해법이 아님
- 복잡도·디버깅·비용 대비 효용을 신중히 따져야 함
5. Universal Verifier for Agent Benchmarks (Microsoft)

배경
- 에이전트 벤치마크는 실패를 성공으로 잘못 판정하는 경우가 많음
핵심 아이디어
- 인간 평가 기준에 근접한 범용 검증기
4가지 원칙
- 비중복 평가 기준
- 과정(Process)과 결과(Outcome) 분리
- 통제 가능/불가능 실패 구분
- 전체 스크린샷을 단계적으로 평가
결과
- 기존 검증기 false positive: 22~45%
- Universal Verifier: 거의 0%
의미
- 에이전트 평가·RL 보상 신뢰성 문제를 구조적으로 해결
6. Scaling Coding Agents via Atomic Skills

배경
- GitHub 이슈 등 큰 태스크로만 학습 → 과적합·전이 약함
핵심 아이디어
- 코딩을 5개 원자적 기술로 분해
- 코드 위치 찾기
- 코드 수정
- 테스트 생성
- 이슈 재현
- 코드 리뷰
학습
- 다중 기술을 공동 RL로 최적화
결과
- 평균 성능 +18.7%
- 보지 않은 복합 태스크에도 강함
의미
- “태스크 단위 확장” 대신 기초 기술 단위 확장이라는 새로운 스케일링 전략
7. Agent Skills in the Wild

배경
- 데모에서는 스킬 기반 에이전트가 매우 강력
연구 질문
- 스킬이 3만 개라면?
결과
- 문제는 실행이 아니라 검색
- 스킬 수 증가 → 성능 저하
- 실제 환경에서는 거의 no-skill과 비슷
의미
- MCP 같은 스킬 생태계에서 병목은 발견(discovery)
- “많은 도구”보다 “잘 고르는 능력”이 중요
8. MedGemma 1.5 (Google)
배경
- 의료 데이터는 멀티모달·3D·시계열이 핵심
확장된 기능
- 3D CT/MRI
- 병리 Whole-slide image
- 시계열 흉부 X-ray
- 의료 문서(EHR)
성과
- 병리: +47% macro F1
- EHR QA: +22%
의미
- 의료 AI를 위한 범용 오픈 파운데이션 모델
- 연구·산업 양쪽 모두 활용 가능
9. LightThinker++
배경
- 긴 추론 = 높은 비용 + 불안정성
핵심 메모리 연산
- Commit: 추론 요약 저장
- Expand: 필요 시 재확장
- Fold: 컨텍스트 압축
결과
- 토큰 사용량 −70%
- 정확도 +2.42%
- 장기 에이전트 태스크 안정성 크게 개선
의미
- 추론 = 연속 텍스트가 아니라 메모리 조작 문제
10. Thinking Mid-training (Meta FAIR)
배경
- 추론은 post-training에서 “늦게” 학습됨
핵심 아이디어
- 사전학습 중간에 추론을 공식 능력으로 도입
방법
- 데이터에 추론 삽입
- SFT
- RL로 “언제 생각할지” 학습
결과
- LLaMA-3 8B에서 3.2배 성능 향상
의미
- 추론은 보정이 아니라 본능처럼 길러야 하는 능력
'AI > NLP' 카테고리의 다른 글
| NLP paper review (3/30~4/5) (0) | 2026.04.06 |
|---|---|
| NLP paper review (3/23~3/29) (0) | 2026.03.30 |
| NLP paper review (3/9~3/15) (0) | 2026.03.16 |
| NLP paper review (3/1~3/8) (0) | 2026.03.10 |